

Gestion des textes
Gestion et réutilisation multiple des textes indépendamment des médias
Les textes sont saisis indépendamment des médias et gérés de façon granulaire afin de pouvoir les utiliser de nombreuses fois et de réduire considérablement les efforts en maintenance. La diversité des textes peut être clairement structurée au moyen de catégories, versions et langues, et gérée dans la base de données crossbase dans toutes les langues du monde indépendamment des médias. Grâce à XML et Unicode, les textes de la base de données crossbase peuvent être gérés de manière neutre sur le plan des médias et dans toutes les langues.
Gestion des textes
Pour chaque catégorie de texte, il est possible de définir un nombre maximum de caractères, si les textes sont générés automatiquement ou saisis manuellement et l’objet pour lequel ils peuvent être saisis, par exemple pour un article, un groupe d’articles ou une page De même, il est possible de définir si les textes sont générés ou gérés manuellement et sur quel objet ils peuvent être gérés. Afin de pouvoir utiliser les textes pour différents médias, langues et marchés, ils sont regroupés en éléments de texte neutres par rapport au média et spécifiques à la langue, et marqués de manière spécifique au marché.
Éditeur de texte
L’éditeur de texte XML intégré comprend de nombreuses fonctions pour saisir et formater des textes. La rédaction en mode WYSIWYG est similaire à la rédaction dans MS-Word. Le texte est enregistré avec des balises indépendamment des médias. Les formatages de texte peuvent être organisés dans des groupes de styles. Les césures peuvent être définies dans Adobe InDesign à partir de dictionnaires spécifiques à chaque langue. L’aperçu donne à l’utilisateur une impression du formatage spécifique à la sortie. Les fragments de texte et les caractères spéciaux fréquemment utilisés peuvent être stockés sur des boutons et donc rapidement insérés.
Textes et éléments de texte
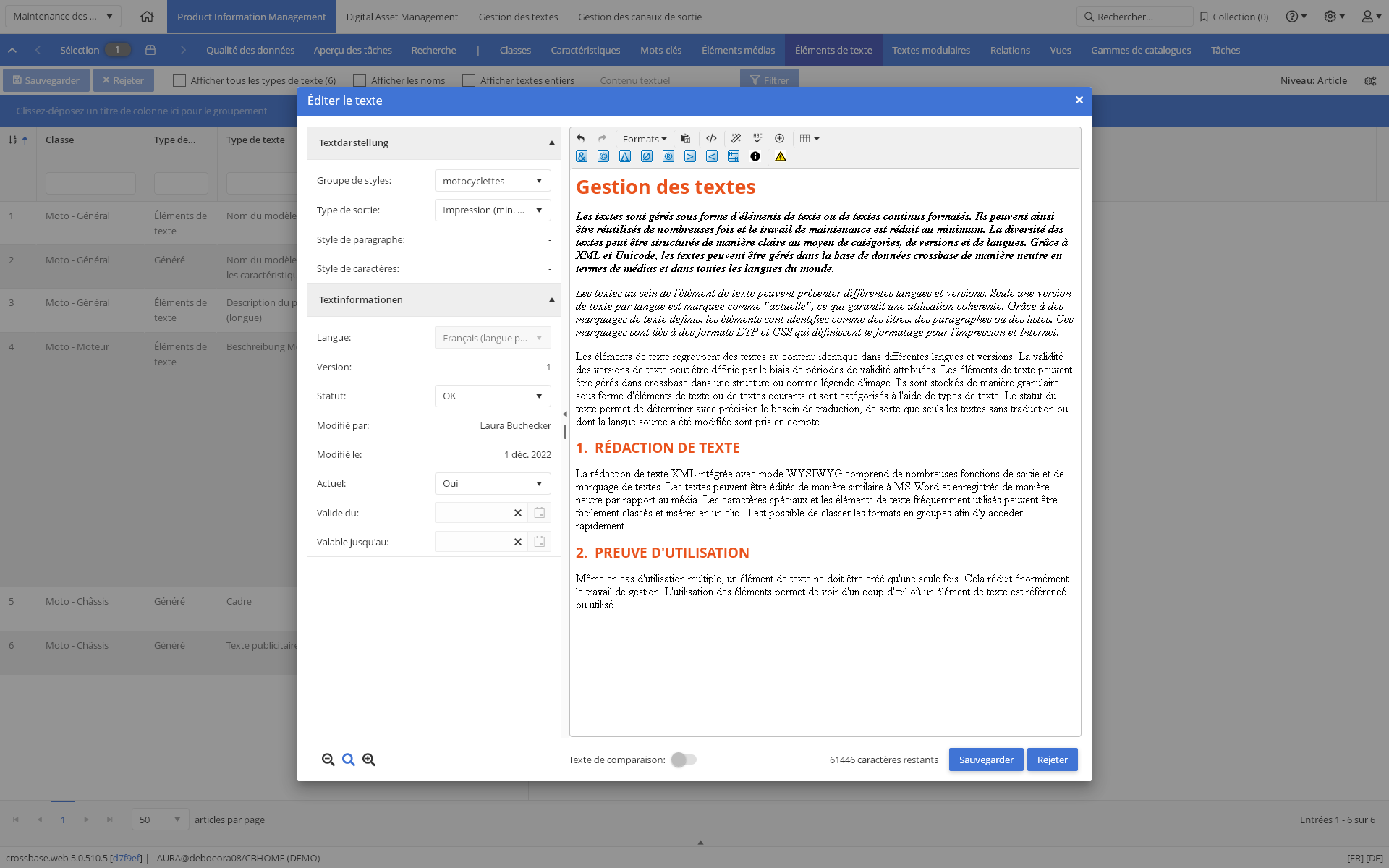
Les textes d’un élément peuvent avoir des langues et des versions différentes et peuvent contenir des balises de texte pour, par exemple, les titres, les paragraphes et les listes. Ces balises sont affectées à des formats InDesign et CSS spécifiques au média pour contrôler le formatage sur papier et sur Internet. L’élément de texte peut être utilisé de nombreuses fois, par exemple pour un produit, pour une publication ou pour une page HTML. Lors de modifications ou additions aux textes, ces liens sont conservés et les modifications du texte sont répercutées sur toutes les utilisations.
Structure des textes
Les éléments de texte peuvent être créés ou importés dans crossbase, directement dans une structure ou comme légende d’image d’un élément média. Les éléments de texte sont stockés individuellement sous forme d'éléments de texte ou de textes courants et sont catégorisés avec des types de texte. Vous pouvez utiliser les périodes de validité attribuées pour contrôler la validité des versions de texte. Le statut du texte permet de déterminer avec précision les besoins en traduction.
Textes avec variables
Les textes relatifs au produit peuvent contenir divers textes modulaires sous forme de variable. Si un texte avec une variable est lié à un produit, la valeur correspondante gérée sur le produit est insérée à la place de la variable.
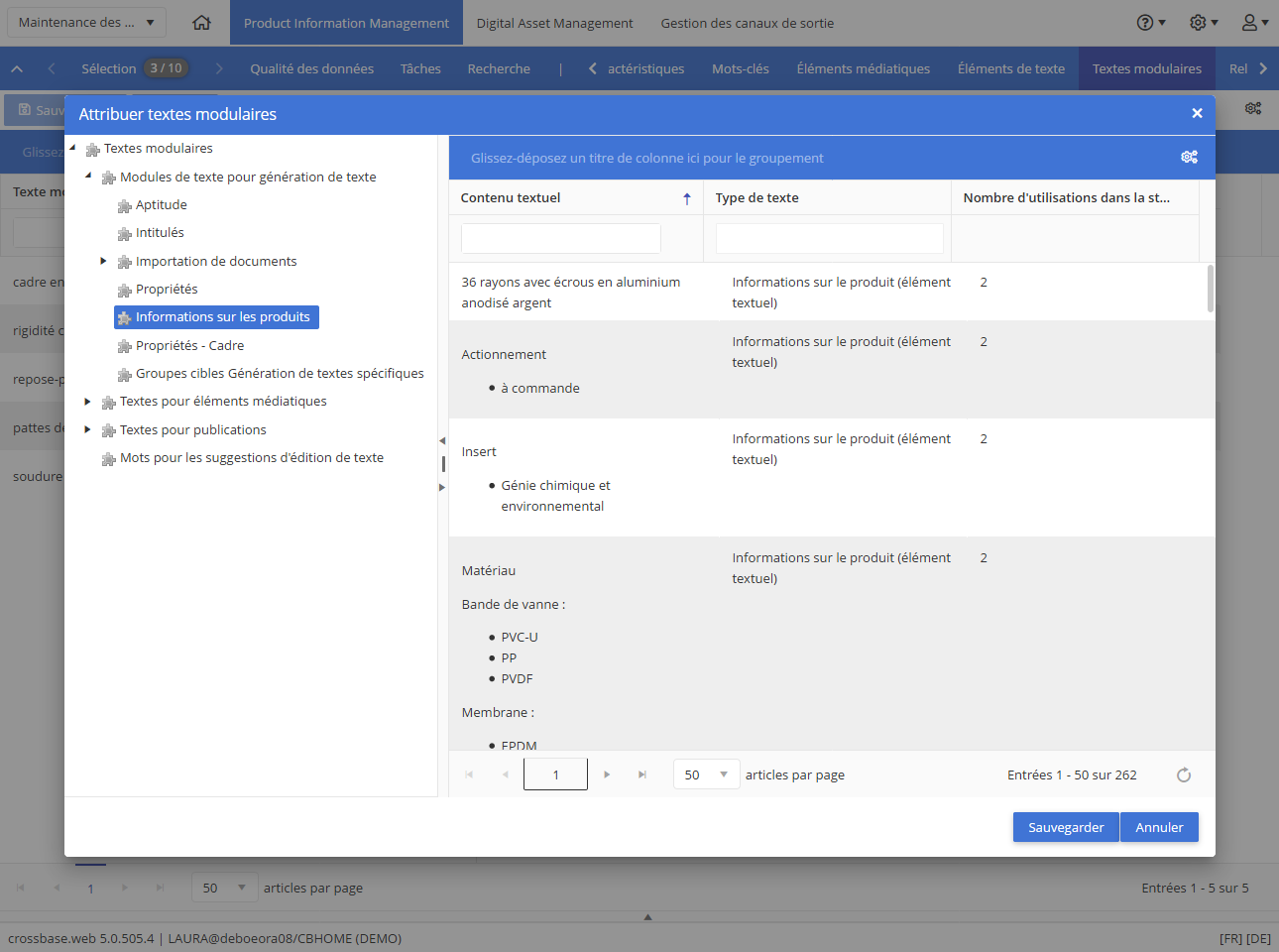
Textes modulaires
La réutilisation de composants de texte pour les produits peut être contrôlée automatiquement. Lors de la gestion des données de produits, il est possible de sélectionner les composants via la structure ou la recherche plein texte et de les attribuer à un produit, un dessin ou un tableau dans un ordre précis.
Structure éditoriale
Le contenu éditorial peut être maintenu dans une structure analogue aux textes modulaires, indépendamment du produit. La structure contient des unités logiques, qui se constituent de corps de texte, de graphiques, de dessins, de tableaux, etc. et qui peuvent être utilisées comme composants à de nombreuses reprises dans les publications. L’ensemble de l’unité logique peut être marqué en fonction du pays afin de permettre une communication ciblée et spécifique au marché. En reliant une ou plusieurs unités logiques à une suite de pages, la documentation technique spécifique à un pays peut être compilée rapidement et facilement.
Connexion directe à ChatGPT
Une interface directe entre crossbase et ChatGPT Pro permet d'expérimenter la génération automatique de textes et leur utilisation possible. Nos tests ont montré que la création de textes courants utilisables à partir de la saisie d'éléments de texte ou de textes de liste fonctionne déjà très bien.
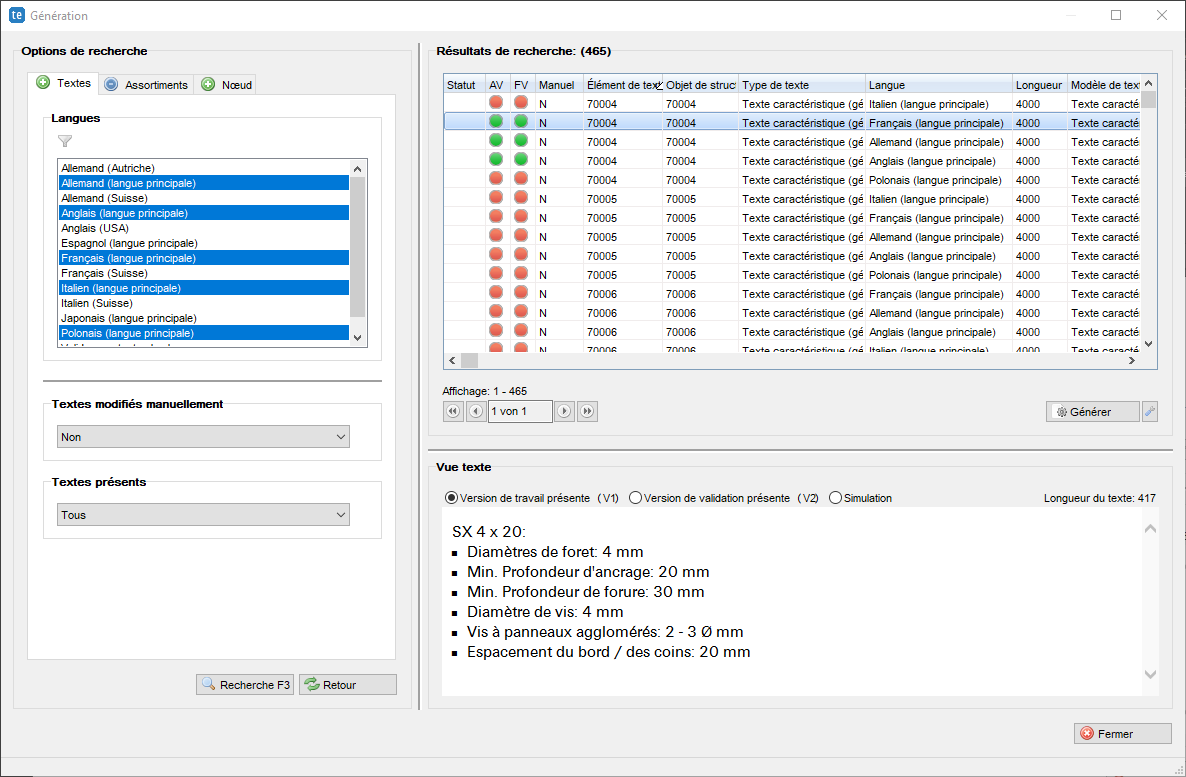
Gestion de la terminologie
La gestion de la terminologie crossbase assiste les rédacteurs et les traducteurs en leur fournissant un système de gestion de la terminologie. Les termes sont ainsi gérés de manière centralisée et utilisés correctement quel que soit le domaine. Ainsi les termes sont utilisés de manière cohérente dans la communication de l’entreprise. Le travail de terminologie commence avant la traduction afin de réduire au maximum les coûts de traduction et de relecture. Les systèmes de mémoire de traduction (TMS) ne développent leur plein effet que lorsque les termes sont utilisés de manière cohérente dans la langue source. Pour cela, il est judicieux d’extraire les termes des textes d’origine, de les saisir de manière centralisée dans la base de données crossbase, de les uniformiser, de les décrire (également avec des termes négatifs, des synonymes, etc. classables) et de les mette en permanence à disposition du TMS.
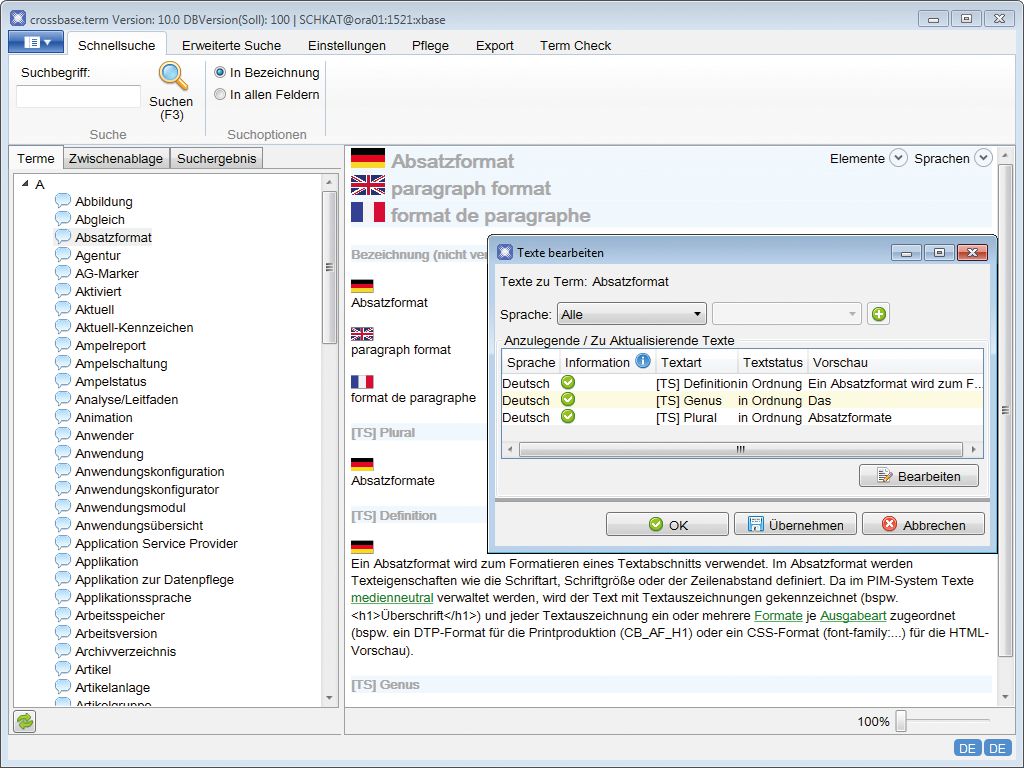
Vérificateur orthographique
crossbase dispose d’un vérificateur orthographique intégré basé sur des dictionnaires de Hunspell. Par défaut, les dictionnaires Hunspell sont disponibles pour les langues suivantes : français, allemand (DE, CH, AT), anglais (US, GB), italien, polonais, portugais et espagnol. D’autres dictionnaires peuvent être ajoutés à tout moment. Comme alternative au correcteur orthographique intégré, Congree peut être intégré via une interface en tant que logiciel tiers nécessitant une licence.
Nous respectons votre vie privée
Ce site web n'utilise pas de cookies pour collecter les données ou le comportement des visiteurs !
